Dark Web Map: Exploration
Dark Web Map Series
In today’s installment of the Dark Web Map series, I am going to take a deeper dive into its contents. Mainstream coverage of the dark web portrays it as a spooky morass of stolen identities and top secret documents. But is that a fair representation? My goal here is to draw objective conclusions and to let the data speak for itself.
Surveying The Dark Web
In the first post of this series, I looked at a few random examples of dark web sites. The handful of examples in that article showed a wide range of topics on the dark web: from the banal (an Indian post office) to the illicit (underground casinos) to the pro-democratic (anonymous sourcing for journalists). Of course, that was just a handful of examples out of the 6.6K sites on the map.
In this post, I will develop a broader and more quantitative approach to determining what’s out there on the dark web. Let’s start by building a topic model. Topic modeling is a natural language processing (NLP) technique that tries to make sense of a large collection of documents by finding common topics and the keywords associated with each topic. I will treat each dark web page as a “document” and extract the text content from each page (ignoring the HTML markup) with some cleanup before building topic models. (For full details, take a look at this Jupyter notebook.)
Below, I have used a topic modeling algorithm to produce the top 25 topics for all of the onions, i.e. the topics that are most common on the dark web. This allows for quick summarization of this large collection of data.
| ID | Score | Keywords |
|---|---|---|
| 1 | 121 | tor, post, forum, 2018, 2017 |
| 2 | 71 | daniel, hosting, bitch, ~brown, eof |
| 3 | 57 | btc, investment, lotery, 100, bonus |
| 4 | 55 | congratulate, demo, dark, html, sign |
| 5 | 49 | 403, forbid, nginx, permission, unix |
| 6 | 44 | register, login, password, logout, username |
| 7 | 44 | card, credit, number, birth, atm |
| 8 | 44 | $, key, person, email, plan |
| 9 | 41 | login, password, speedstepper, captcha, surround |
| 10 | 41 | coin, blender, mix, deposit, transaction |
| 11 | 40 | >, <, div, class=, javascript |
| 12 | 37 | file, apache2, configuration, web, default |
| 13 | 36 | 502, disconnected, bad, gateway, nginx |
| 14 | 34 | nginx, 504, gateway, 502, welcome |
| 15 | 32 | index, modify, size, description, 2017 |
| 16 | 31 | respond, didn, 504, gateway, awesome |
| 17 | 31 | password, session, log, inactivity, length |
| 18 | 30 | submit, document, click, securedrop, slider |
| 19 | 29 | request, url, port, apache, debian |
| 20 | 26 | 404, error, nginx, page, internal |
| 21 | 25 | http, maintainance, untill, deep, tor |
| 22 | 19 | 401, authorization, nginx, require, unauthorized |
| 23 | 19 | test, myhacker, visit, page, demonstration |
| 24 | 17 | room, red, join, leave, day hour |
| 25 | 15 | invalid, header, client, receive, credential |
Topic modeling is an inherently noisy process. The algorithm looks for words that occur together more frequently than by random chance. This process misses some obvious connections, like ontologies of concepts (e.g. the relationship between “cryptocurrency” and “bitcoin”) and translations of keywords into different languages (“drugs” vs “drogas”).
Nevertheless, some of the topics above are interpretable:
- Topic #2 is related to Daniel’s Hosting, which is a service that hosts dark web sites.
- Topic #7 seems to be related to credit card numbers, ATM pins, and birthdays.
- Topic #18 is related to SecureDrop, which is a service that lets anonymous sources submit documents to journalists.
- Topic #24 is based on the infamous Red Room urban legend.
Some topics are difficult to interpret or are the result of errors on the onion web pages:
- Some topics (e.g. #1 and #4) are difficult to interpret. It’s not clear how those keywords are related to each other.
- Several topics (#5, #13, #14, #16, #20, and #22) are related to errors stemming from misconfigured webservers.
- Topic #11 is derived from web pages that have incorrectly formatted HTML markup.
One way to interpret a topic is to view some of the documents associated with that topic. Let’s try that for topic #4 by listing its top 10 documents:
1 congratulate you you have made site the dark side …
2 congratulate you you have made site the dark side …
3 congratulate you you have made site the dark side …
4 congratulate you you have made site the dark side …
5 congratulate you you have made site the dark side …
6 congratulate you you have made site the dark side …
7 congratulate you you have made site the dark side …
8 congratulate you you have made site the dark side …
9 congratulate you you have made site the dark side …
10 congratulate you you have made site the dark side …
Hey, this “topic” is just the same exact web page repeated over and over! What is going on here? Here’s an example of one of these pages in the map:
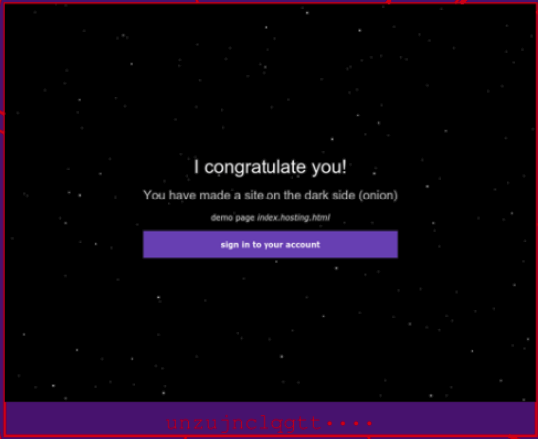
So this looks like a tool that generates an onion site for you, and it has default content that congratulates you. (How sweet!) If you zoom out, you can see how many different copies of this same page exist:

That is 184 identical pages! This suggests any onions running identical web pages are going to have undue weight on my topic model, leading to a distortion. Overall, this approach gives us some intuition about what’s on the dark web (bitcoin, stolen credit cards, red rooms) but it’s muddled by misconfigured websites and repeated pages. Let’s take a step back and think about repetition on the dark web.
Repetition & Clustering
Why do all of the congratulations pages cluster together in the first place? As explained in the previous post, the map is organized by placing sites that are structually similar close together and connecting them with a line. When many sites are all similar or identical to each other, they form into clusters.
If I can understand these clusters better, maybe I can solve some of the problems that arose from my first attempt at topic modeling. I will eyeball some of the clusters and then see if I can formalize this analysis later.
First, let’s take a look at the biggest cluster, which appears right in the middle of the map. This cluster has two lobes: a large bottom lobe and a smaller top lobe. Let’s zoom in a bit to see it better.

In order to get a sense of what kinds of web sites are in this cluster, I have highlighted three different areas of the cluster in yellow. Let’s zoom into those three areas.
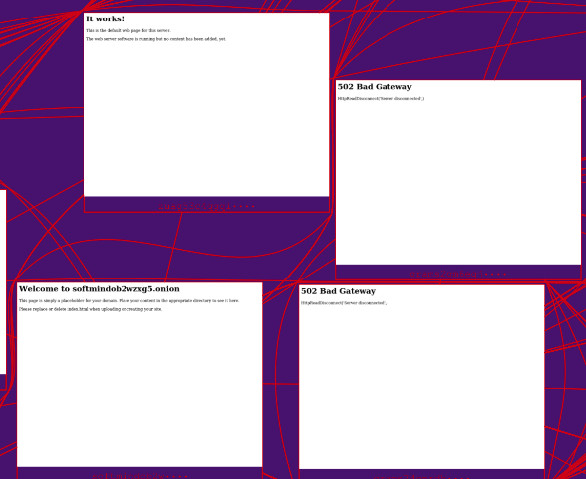
This first zoom is from the top lobe of the big cluster. It displays 4 very similar pages: a bold heading at the top followed by a line or two of text. Two of these pages display an error, and the other two display default messages that indicate a site has been installed but no content has been added. Most of the pages in this top part of the big cluster look a lot like the 4 pages seen here.

This second zoom is from the bottom lobe of the big cluster. It displays 4 very similar web pages that each contains a line of text that contains a link. Most of the pages in this bottom part look a lot like the 4 pages seen here.
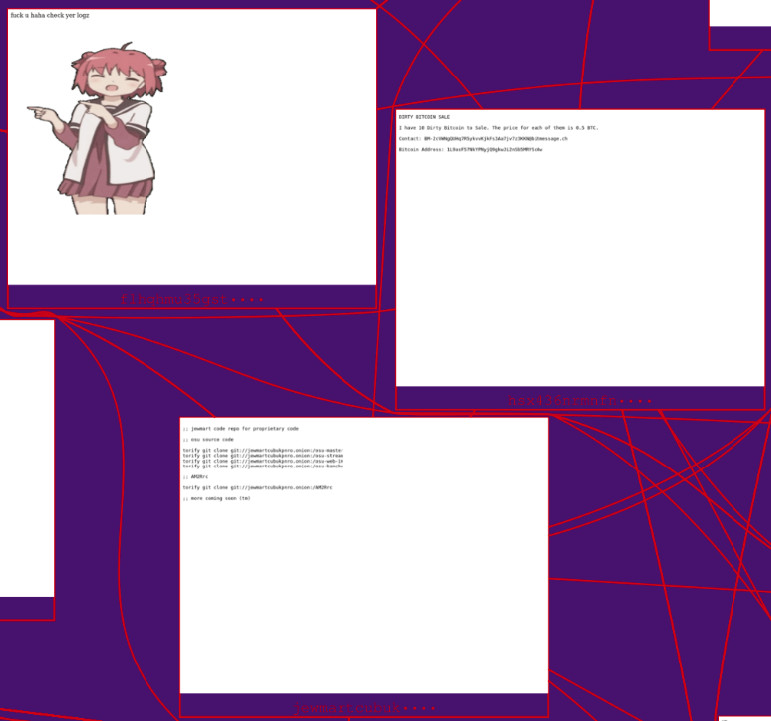
Zoom #3 comes from the middle area between the top and bottom lobes. These pages are all quite simple: a few lines of text and (in one case) an image. This demonstrates the concept of clustering very well:
- Pages in top and middle parts are similar to each other.
- Pages in middle and bottom parts are similar to each other.
- Pages in top and bottom parts are not similar to each other.
Therefore, the map organizes this cluster into these two different lobes, connected together by the middle pages.
The next cluster contains marketplaces that appear to sell illegal goods, such as counterfeit currency and passports. This cluster is smaller than the previous cluster, but it has the same two-lobed structure.

This cluster demonstrates the way I measure similarity: even though the sites look different and sell different products, they still share common page structure. For example, each page has a title at the top, four buttons (Products, Help, Register, and Login), a picture, and a table of prices.
The next cluster is an apparent bitcoin scam. Compare the shape of this cluster to the shape of the previous two clusters. The circular shape (i.e. lack of lobes) indicates that these sites are all nearly identical to each other.
Why are there so many duplicated bitcoin scams on the dark web? Is it one scammer who is operating a bunch of different sites, or are multiple scammers copying each other (and possibly trying to scam the scammers)?
Here is another circular cluster containing “red room” sites, one of the topics identified by our earlier topic modeling effort.


I have no reason to believe that these red rooms are real. The interesting question is why there are so many different red room sites that all have identical structure. The clustering and shape of the red room cluster has more in common with the bitcoin scams than with legitimate sites.
So what can we observe just by looking at these different types of clusters? I see that largest clusters on the dark web are largely just noise: sites that contain spurious error messages, template pages from when they were set up, or blank/incoherent content. Other large clusters contain cloned sites with indicators of scams and/or criminality.
Formalizing Clusters
Now that I have skimmed over a few clusters, let’s formalize the analysis a bit. I will begin by plotting cluster sizes in a histogram.
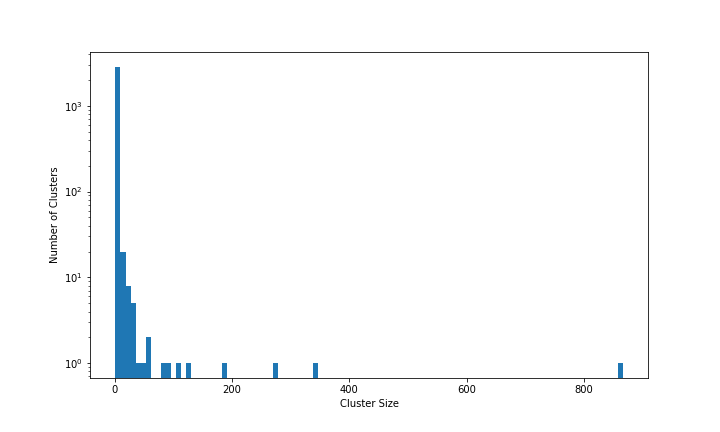
The horizontal axis shows cluster sizes. The leftmost column represents small clusters (one or a few sites) and the rightmost column represents the very biggest cluster (866 sites). The vertical axis shows cluster sizes in log scale: the tallest bar is almost 3,000 and the shortest bars are 1. (This histogram is dependent on the thresholding described in my previous blog post.)
The data illustrate how unusual the large clusters (>50 sites) are. There are only 10 of these large clusters, but they contain roughly one third of all the sites in the Dark Web Map! The middle third of clusters have between 2 and 49 sites each. The remaining third are clusters of size 1, i.e. a single site that is not connected to any other sites.
The distribution reveals an important caveat for my topic modeling effort: the topics are biased towards sites that are heavily repeated. E.g. if there are 184 identical “congratulations” sites on the dark web, then my topic model will be biased towards the “congratulations” topic.
Topic Model Redux
Now that I know that repetition of similar sites biases my topic model, can I use my knowledge of clustering to build an unbiased topic model? Here’s the gameplan: for each cluster (including clusters of size 1), pick one site at random to represent that cluster and then throw the rest away. This process should reduce the bias towards cloned sites, error messages, and other semantically meaningless junk.
The new top 30 topics are:
| ID | Score | Keywords |
|---|---|---|
| 1 | 177 | address, website, want, send, need |
| 2 | 50 | password, username, register, log, forget |
| 3 | 49 | card, credit, balance, buy, price |
| 4 | 44 | post, topic, view, board, total |
| 5 | 43 | >, <, br, div, javascript |
| 6 | 39 | que, para, por, con, como |
| 7 | 39 | forum, member, mybb, board, thread |
| 8 | 37 | btc, address, transaction, wallet, send |
| 9 | 37 | $, 000, buy, 100, personal |
| 10 | 36 | server, port, apache, xmpp, index |
| 11 | 36 | die, und, der, ist, von |
| 12 | 36 | kazino, igry, tak, den, prosto |
| 13 | 35 | key, pgp, public, block, begin |
| 14 | 35 | div, class=, <, 0px, > |
| 15 | 33 | vous, les, des, sur, pas |
| 16 | 33 | file, upload, image, size, png |
| 17 | 32 | http, www, wiki, php, index |
| 18 | 29 | eur, mg, product, pure, 100 |
| 19 | 28 | cart, add, sort, sale, g |
| 20 | 27 | host, daniel, website, hosting, blog |
| 21 | 25 | sign, account, remember, address, forget |
| 22 | 24 | debian, package, debconf, update, dsa |
| 23 | 23 | casino, game, online, money, play |
| 24 | 21 | hello, world, wordpress, find, placeholder |
| 25 | 20 | `, ysh, hblvg, =, wly |
The topics are noticeably better now!
- Topic #3 appears to be stolen credit cards.
- Topic #4 depicts common web forum terms.
- Topic #8 is related to bitcoin.
- Topic #12 is Russian-language casinos. (“kasino” is the romanized form of “казино”, which is the Russian word for casino.)
- Topic #13 contains cryptography terms related to PGP software.
- Topic #16 reflects sites where users upload and host images.
- Topic #18 appears to reflect illegal drug sales.
Other topics are still problematic:
- Topics #5 and #14 show that broken HTML is common on the dark web.
- Topics #6 and #11 are short, meaningless words in Spanish and Russian, respectively. (This does suggest that Spanish and Russian are popular languages on the dark web, after English.)
- Topic #25 is completely unintelligible.
These sorts of artifacts are pretty typical for topic modeling. For a quick analysis, though, this is a pretty good start. Let’s dig deeper on a couple of these topics, starting with #16. How to confirm my intuition about what this topic means? Let’s look at the top 10 pages associated with this topic:
| Rank | Onion | Page Text |
|---|---|---|
| 1 | th2yjjp5cmso**** | kgdskill home files contacts… |
| 2 | filesto37i2x**** | upload files home uploads chat online test short urls onion link list mail xmpp hosting tutorials hi… |
| 3 | bayfilesittw**** | upload 300 files… |
| 4 | opfiless3tg2**** | login sign file uploader sign have private folder download pass optional upload features files after… |
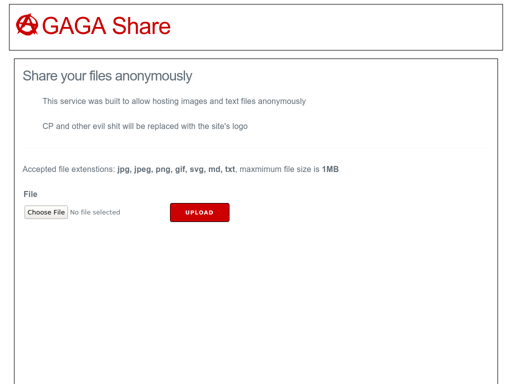
| 5 | share3g3ssxs**** | gaga share share your files anonymously this service was built allow hosting images and text files a… |
| 6 | popfilesxuru**** | galaxy2 donate myfiles popads popfiles the simplest file host choose username password username http… |
| 7 | ln6vyadk4hv3**** | image upload allowed jpeg gif and png multiple files upload supported total upload size 50mb… |
| 8 | helpu2ov4khc**** | new very soon links information about about chats and forum chat betachat not forum image hosting im… |
| 9 | atlayofke5rq**** | sign login forgot password login terms use privacy policy contact about blog why are wall images bee… |
| 10 | dmcabaynptm5**** | browse upload help faq forum contact guest register login you are not logged you can still upload bu… |
These pages do indicate that this topic centers around private image uploading and hosting. Here is a screenshot of the fifth one:
Finally, let’s dig deeper on topic #25, which looks like gibberish. The top 10 documents are:
| Rank | Onion | Page Text |
|---|---|---|
| 1 | fpqmnpsb7fjq**** | syt khbry thlyly khlmh brgdhry swrty khh sr`t rtbt yntrnty shm khm twnyd nskhh khm hjm jht dstrsy mt… |
| 2 | nwsw6u3emdvr**** | lpny yvshb |
| 3 | 3jdxfoiidvcz**** | bwbh l`rb lry ysyh mwdw`t link link link nsy mhmh rwbt tsl tbr` ldyb wyb ldyb wyb shbkh twr shbkh mt… |
| 4 | darkblogkjmw**** | hblvg hpl hbyt vdvt tsrv qshr prsmv pvrvm hblvg hpl hblvg hpl nvld b`qbvt rdyph khbrynv nkhqrym vn`n… |
| 5 | autshpxnxhuv**** | skip navigation skip content autoshop automatic purchases search for menu home all products cart che… |
| 6 | kamellkelv2h**** | kamel zitouni kamel zitouni kamel zitouni mrhb smy zytwny kml `ysh ljzy bwly wrql whwyty mmrs lshdhw… |
| 7 | vmfucmt62525**** | khbr lmslmyn mwq` mstql y`ny khbr lmslmyn mry tqryr mswr khbr lmslmyn l`m swtyt ltrykh ljhdy qbl lkh… |
| 8 | 64cptkueswgy**** | jysh mhmd wwrywrz lmqds d`w ll`bd lrhmn lrhym l`ly read more wnhn nshhd mkn `bdtn sqwt wnr~ khwnn kh… |
| 9 | x36n2vixwf2y**** | hello world you are reading this you either are the sans sec487 osint course and you are starting on… |
| 10 | wpcxzq4ykmsx**** | mwq` gyr rsmy l`rd sdrt ldwl lslmy categories |
Although there are two recognizable sites in here (#5 and #9), the others still look like gibberish to my eyes. Let’s look at screenshots of a couple of these sites:
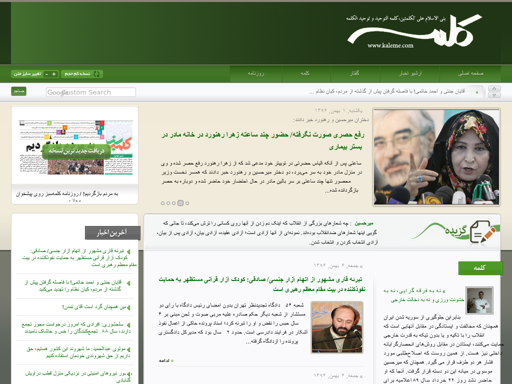
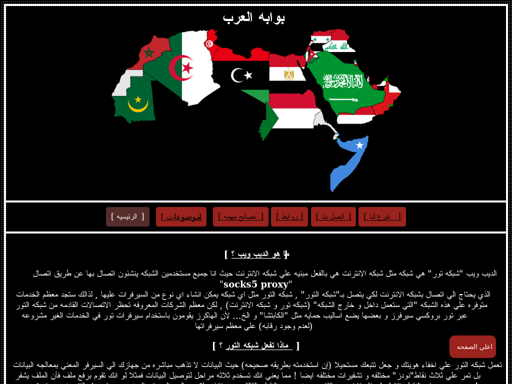
Now I can clearly see that these are Arabic sites. As part of the pre-processing, I romanized foreign alphabets, which is what causes these sites to look like gibberish to an English speaker. This topic suggests that Arabic is another popular langauge on the dark web.
Drawing Conclusions
As I explained above, topic modeling is a noisy process with significant limitations. Furthermore, the dataset I have here is limited by the fact that I only look at the home page of each site. Indeed, topic #2 appears to relate just to login screens, suggesting that there may be a lot of content on the dark web that I can’t even see without acquiring a login. My dataset does not include the traffic going to these websites, so I have to assign equal weight to the most popular and least popular sites alike. And, of course, if an onion operator really wants to make his/her site hard to find, my simple data collection process is likely to miss it.
I assume that these biases in my process probably underrepresent some categories of content, including drug marketplaces, pornography, and child exploitation. Browsing visually through the Dark Web Map, for example, demonstrates the prevalence of pornography. Porn probably doesn’t show up in the topic model because that content is mostly visual and the associated terminology is broad.
So what conclusions can I actually draw? The topic model does reveal the prevalence of certain functional roles in the dark web ecosystem: forums, chat rooms, marketplaces, and file/image hosts. These functional roles certainly support both licit and illicit activities on the dark web. For example, porn is underrepresented in topic model, but presumably that content is distributed through the forums, chat rooms, and file/image hosts.
The topic model also shows which written languages are prominent on the dark web. English and Russian are unsurprisingly dominant. The importance of Spanish, Portugese, and Arabic definitely caught me by surprise, as did the notable absence of Chinese.
Thanks for following along today! I hope this was informative without being unbearably technical. If you want to see more detailed analysis, take a look at this Python notebook that shows how I derived the results in this post.